Neurite Identification Tool (NIT)
Identify secondary neuronal lineages in a Drosophila brain
Software installation:
|
|
See video tutorials on TrakEM2, and a complete manual.
Update 2010-06-08: uploaded new T2-NIT.jar, which works well with fiji's updated weka library. Thanks to Ignacio Arganda for extensive help.
Update 2012-03-14: uploaded new T2-NIT.jar with improved capabilities, namely the ability to specify your own reference libraries with the file plugins/NIT-libraries.txt, which declares one library per line.
This page provides support material for the published work Cardona A, Saalfeld S, Arganda-Carreras I, Pereanu W, Schindelin J, Hartenstein V. 2010. Identifying neuronal lineages by sequence analysis of axon tracts. Journal of Neuroscience 30(22):7538-53. Get the [PDF].
Semiautomatic identification of secondary neuronal lineages:
STEP 1: Load a confocal image stack into TrakEM2
| Open Fiji and go to "File - New - TrakEM2 (blank)". You will get a "TrakEM2" window and a "canvas" window (in black) in the front. |
 |
| Drag and drop a confocal image stack onto the black canvas window. A dialog pops up, asking for space calibration and other settings. Most likely defaults are correct; just push "OK". A second dialog will ask whether to adjust the current section thickness -- just say yes. (See the apendix for the import stack dialogs options.) The stack will now be loaded in the canvas window. Notice that the "TrakEM2" window now has a list of "layers", where each layer represents a section in the image stack. To navigate the display, use:
|
 |
 |
STEP 2: Create a lineage template
First we create a template lineage object with a polyline data type in it. Then later on we instantiate as many lineages as we need.
You may skip this step by downloading the neuropile.dtd file and creating a new TrakEM2 project using it as a template (from "File - New - TrakEM2 (from template)").
| Go to the "TrakEM2" window and right-click on the "anything" node (to the left). Choose "Rename..." and give the node a new name such as "neuropile". |  |
| Now right-click the just-renamed "neuropile" node and choose "Add new child - New...", and give it the name "lineage". Then, to that new node "lineage", right-click and choose "Add new child - Polyline". |
 |
| In the end we have a template lineage node, which contains a polyline template data type inside. So far these nodes are all abstract: it's just our interpretation and the logic by which we'll structure the segmentation data. |
 |
We need to create the template only once. Later on, templates may be reused by choosing "File - New - TrakEM2 (from template)", or by having more than one TrakEM2 project open and using "Add new child - From project - <name of the project>"
STEP 3: Create a lineage object
By using the nodes in the "Template Tree", we create as many instances of them in the "Project Tree" as necessary. In this tutorial, we create just one.
| Drag and drop the neuropile template node to the project node in the "Project Objects" (be sure to drag it exactly on top). Then drag and drop the lineage template node to the new neuropile in the "Project Objects", and finally drag and drop the polyline template node to the new lineage node. We observe now a new instance of a polyline, with unique identifier "#205". |
 |
| Notice how the canvas window switched to the "Z space" tab, and shows the new polyline object selected (it's panel background is cyan). |  |
Tip: since drag and drop of each element can get tedious, try drag and drop of any low-order node (like a template lineage) and then push the control key before releasing it--all children nodes are instantiated, recursively.
An additional way to do it is by right-clicking on any of the existing nodes in the "Project Objects" and choosing "Add - many...", which has powerful multiple recursive object instantiation possibilities.
STEP 4: Semi-automatic tracing
So far, our polyline object to represent the lineage is empty. We are going to use a semiautomatic tracing tool to click on its first and last points, and find the shortest path.
Start by picking the Freehand tool  . .Make sure as well that the polyline object is selected in the "Z space" tab. Click the panel if necessary, to select it, so that its background is cyan. (When deselected, it's white.) |
 |
| Scroll through sections until finding a good starting point near the cell bodies, then click: a point with a number '1' appears. |  |
| Then scroll sections until finding a suitable end point near the distal end, and click it. Tracing starts, reporting on the status bar. The very first time, a hessian image stack is generated (in the background), which will take a few seconds. Every other autotrace in the same TrakEM2 project won't need to wait. |
 |
|
When done, the traced path is shown. If the lineage axon tract is not unique or is noisy, the automatically traced path may be incorrect. Push control+z to 'undo' it, and try again closer to the starting point. When done, add another point further towards the distal end -- the task is easier and it will likely succeed. |
 |
When a path is very hard to autotrace by just starting and ending points, try to put the ending point closer to the starting point. When done, click further to add another ending point.
With this iterative approach, even hard lineages in a densely labeled brain can be autotraced.
What to do if the autotracing does not work for you:
- Don't autotrace: use the pen tool to add individual points throughout the image stack. (See documentation on Polyline.)
- Or, instead of the polyline data type, use a pipe data type: a set of connected Bézier curves that emulate a tube in space. (See documentation on Pipe.)
STEP 5: Marking fiducial points
In order to compare two or more brains, these must be brought into a common coordinate space. We accomplish this by identifying fiducial points common to all brains under comparison.
For the purpose of identifying secondary lineages in the Drosophila 3rd instar brain, we have defined 8 fiducial points.
| First of all, create a template node named fiducial points, and then right-click and "Add new child - ball" to it. Then, instantiate a fiducial points object by drag and drop from the "Template Tree" to the neuropile node under "Project Objects", and then do the same several times for a "ball" object. Finally, right-click each new ball node in "Project Objects" and rename it. The points will later on be identified by name, so name them carefully. |
 (Click on the image to expand view.) |
| You should have from 4 to 8 points, named: | |
4 easy points:
|
Additional 4 points:
|
Where to add each fiducial point:
| In all the animated snapshots below, dorsal is to the top and medial to the left. All snapshots are to scale with each other. For a general overview, click to enlarge this image: |

|
First locate the 4 easy points, which are the tips and branching point of the mushroom body:
| Point 1: peduncle junction Find the calix (CX) in the posterior end of the brain and then identify the 4 mushroom body lineages as they traverse towards ventral and anterior. Where the 4 lineages come together, forming the peduncle, we set a fiducial point (yellow circle). |
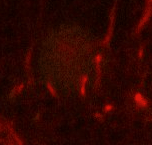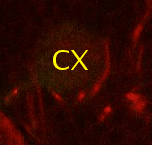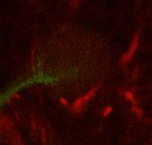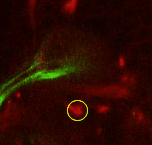 |
| Point 2: mushroom body branch point Follow the peduncle until it splits in two, into the dorsal and medial lobes. Set a point on the branch point. |
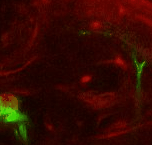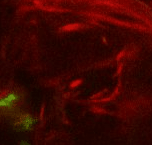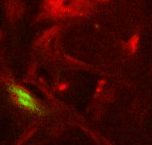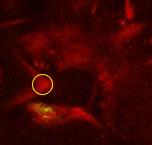 |
| Point 3: dorsal lobe tip Follow the peduncle (ped) to the mushroom body branch point (bp). The dorsal lobe starts towards dorsal; add a point at its tip (dl). |
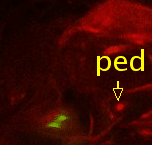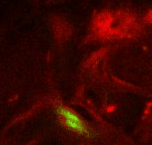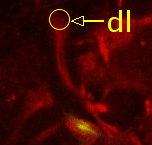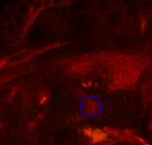 |
| Point 4: medial lobe tip Follow the peduncle to the mushroom body branch point (bp). The medial lobe starts towards medial and reaches the commissure, where we'll put the point (ml). (Here, the left side is the midline between both brain hemispheres.) | 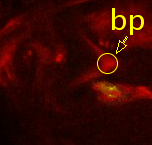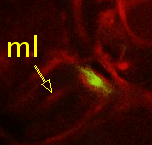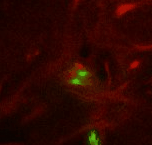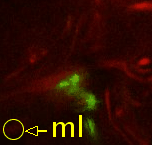 |
Then locate the 4 additional points, which are not required but can greatly improve the accuracy of the identification:
| Point 5: BLD6 junction into great commissure Locate the optic lobe and then follow the great commissure as it emerges from its central part. The BLD6 lineage joins in from dorsal, and then turns towards medial and ventral. |
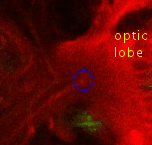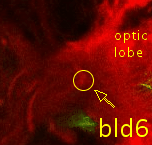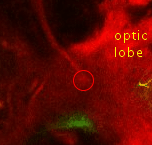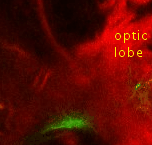 |
| Point 6: BLVa junction Ventral to the great commissure and immediately medial to the optic lobe, there's the 3 BLVa lineages. As they progress from ventral to the entrance of the great commissure into the optic lobe, the come together--add a point there. |
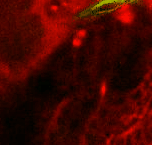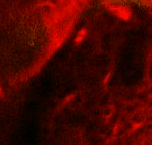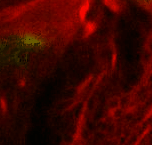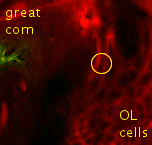 |
| Point 7: BAla split In the anterior ventral region of the brain, there are 2 pairs of lineages, the BAla1/2 and BAla3/4, whose axon tracts first converge and then diverge. Put a point where they start diverging. |
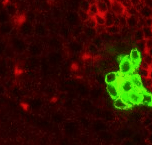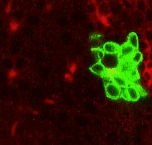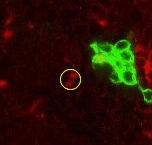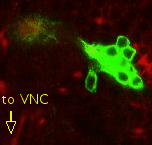 |
| Point 8: DPMm1 entrance into the neuropile Find the commissure (com) between both brain hemispheres. Towards posterior, at a similar level than the calix (CX), there's the massive DPMm1 lineage. Where it enters the neuropile (determined by when its axon tract is no longer surrounded by cell bodies), put a point. |
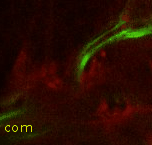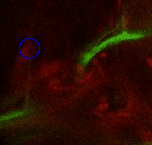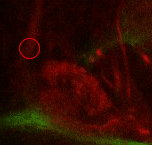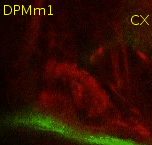 |
A note on extracting fiducial points: there exist techniques for automatic feature exctraction and for finding corresponding features across multiple 3D image data sets (SIFT, MOPS, and SURF come to mind). While using automatically extracted points is fully compatible with our approach, its computationally very expensive (would take minutes or hours to compute for large, high-resolution images) and, in any case, would have to be inspected visually by a human operator.
Furthermore, automatically extracted points are known to not be homogeneously distributed in space; hence, it is possible that most extracted points cover small volumes of the brain, whereas other parts of the brain are poorly or not represented by fiduciary points. Our selection of manually picked fiduciary points covers the whole brain.
In addition, our approach is robust across mutant brains and across different labeling techniques--particularly for the 4 mushroom body points, which are visible even as background in most confocal stacks of fly brain. Furthermore, our approach is robust across imaging modalities: from serial section electron microscopy image data sets to confocal data sets, and viceversa. To date, there aren't any algorithms for the registration of image volumes across imaging modalities.
A whole brain image stack registration approach would face the same problem. If a sufficiently reliable cross-labeling whole-brain registration can be achieved, then finally hand-picked fiduciary points wouldn't be necessary any longer.
STEP 6: Automatic secondary neuronal lineage identification
| Go to the "Project Objects" tree in the "TrakEM2" window, and right-click on the polyline autotraced earlier. Choose "Plugins - Indentify with fiducials". (Or push control+1 to trigger the plugin, being the polyline selected in the canvas.) |
 |
| Shortly a table pops up with the results. Our autotraced polyline has been compared with over 600 traces in the reference database, and the classifier has sorted them all by mean Euclidean distance (last column, titled Avg... in the table) and labeled a few as true matches. (Click on the image to see the whole table, with the names of the true matches.) 4 out of 5 true matches are BAlc:1, the first axon tract of the BAlc secondary lineage. |
 |
| Right-click the top match and choose "Show in 3D". |  |
| Our query trace is in yellow; the top match, BAlc:1, in red. They are very close! The mushroom body lobes are shown in grey to provide spatial reference. When moving the mouse over the lobes, their names are printed in Fiji's status bar. To operate the 3D Viewer, select the hand tool  and then: and then:
|
 |
 .
.Considering how similar and closely apposed the query and match traces are, the suggested annotation BAlc:1 is most likely correct.
STEP 7: Setup parameters (optional)
The NIT program has 4 parameters that can be adjusted using the dialog triggered by the menu item "Plugins - Setup identify with fiducials...":
|
 |
 |
GENERATING YOUR OWN REFERENCE LIBRARY
|
 |
 |
|
 |
Contact:
Albert CardonaAppendix
Import stack dialogs options
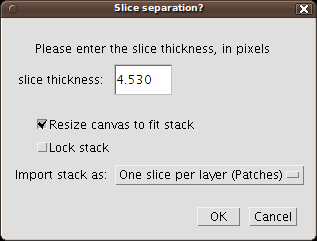
On importing a stack, you'll be presented first with this dialog:
|
|
|
|
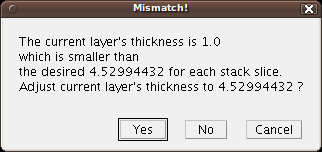
... and then with this other dialog:
| By default, a TrakEM2 layer thickness is 1.0. Now, the stack to import has a larger section thickness. This dialog asks us to confirm that we change the current layer thickness from 1.0 to 4.53, the thickness (in pixels) of the stack slice. |
|